python基础
一、认识python
python的创始人为Guido von Rossum(吉多·范·罗苏姆),俗称”龟叔“,荷兰人。1989年圣诞节期间,在阿姆斯 特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,做为ABC 语言的一种继承。之所以选中 Python(大蟒蛇的意思)作为该编程语言的名字,是因为他是一个叫Monty Python的喜剧团体的爱好者。
1.python优缺点
python优点:
- 简单,易学,易懂,开发效率高:Python容易上手,语法较简单。解释性语言无需编译即可运行。
- 免费、开源:我们运维用的大部分软件都是开源啊
- 可移植性,跨平台:Python已经被移植在许多不同的平台上,Python程序无需修改就可以Linux,Windows,mac等平台上运行。
- 可扩展性:如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或 C++编写,然后在你的Python程序中使用它们(讲完编译型语言和解释型语言区别就容易理解了)。
- 丰富的库: 想产生个随机数? 调库。想操作os? 调库。想操作mysql?Python的库太丰富宠大了,它可以帮助你处理及应对各种场景应用。
- 规范的代码:Python采用强制缩进的方式使得代码具有极佳的可读性。
python缺点:
- 执行效率慢 : 这是解释型语言(下面的解释器会讲解说明)所通有的,同时这个缺点也被计算机越来越强性能所 弥补。有些场景慢个几微秒几毫秒,一般也感觉不到。
- 代码不能加密: 这也是解释型语言的通有毛病,当然也有一些方法可以混淆代码。解决方法: 参考优点的第4条
2.python应用场景
- 操作系统管理、服务器运维的自动化脚本
- Web开发
- 服务器软件(网络软件)
- 游戏
- 科学计算
- 其它领域
二、python安装
1.python安装
官网下载地址:https://www.python.org/getit/
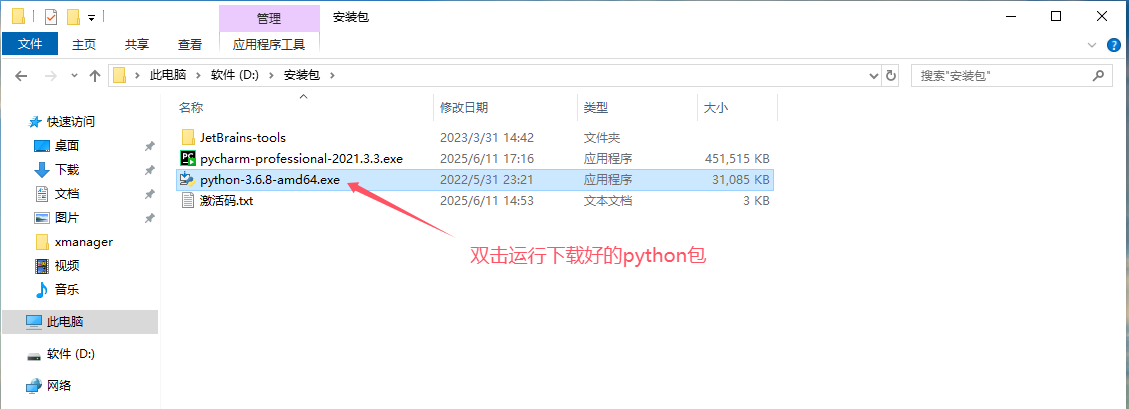
选择自定义安装,勾选环境变量配置
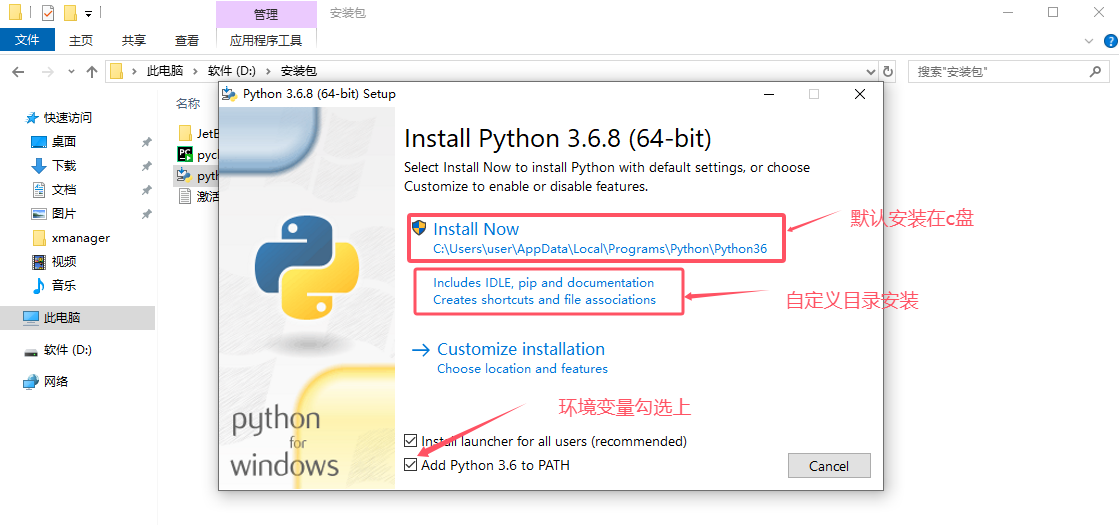
保持默认下一步
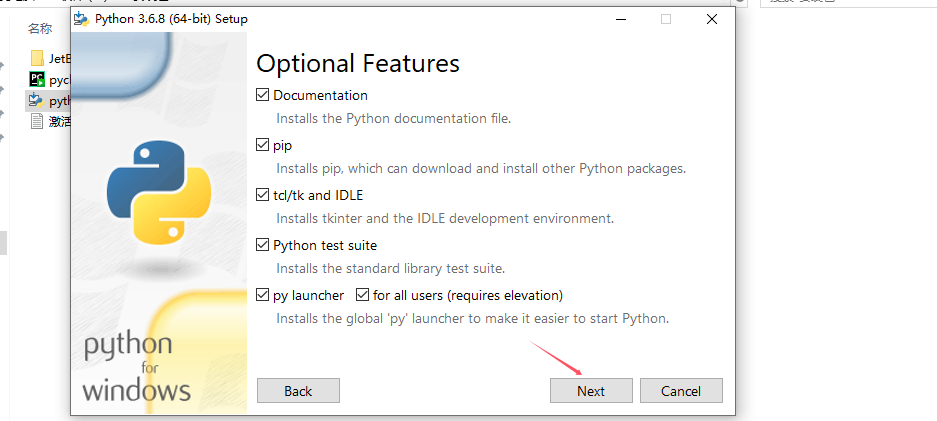
选择安装的地方
出现下图表示安装成功
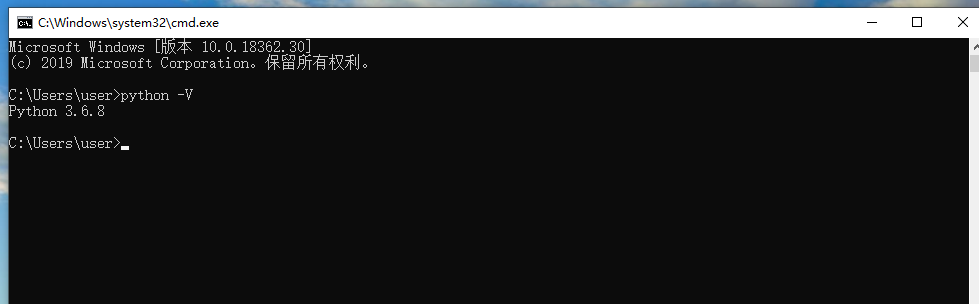
打开终端或命令提示符cmd验证
pip源配置:windows---->c盘---->用户---->你得用户名下创建pip文件夹在文件夹下面创建pip.ini文件
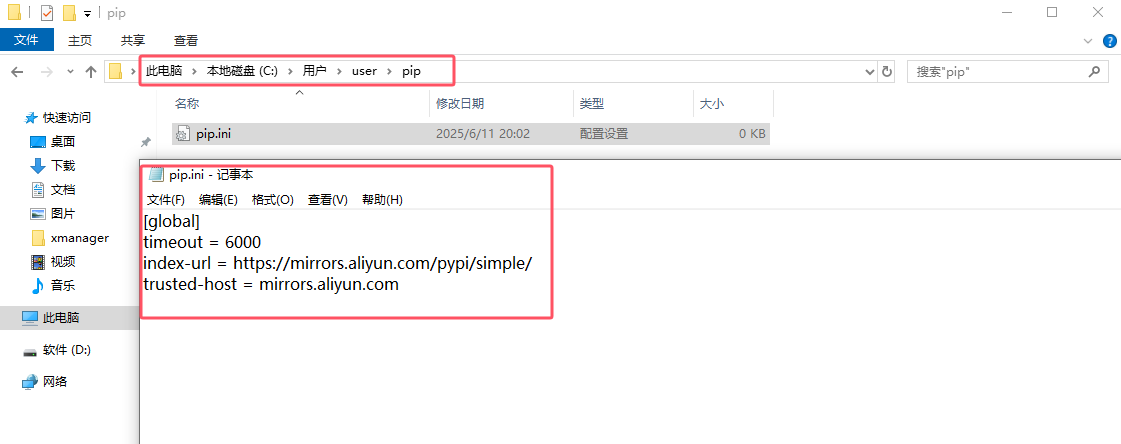
[global]
timeout = 6000
index-url = https://mirrors.aliyun.com/pypi/simple/
trusted-host = mirrors.aliyun.com
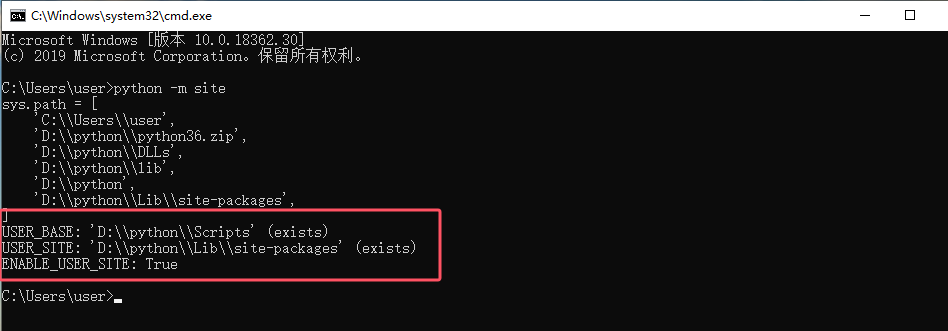
配置pip下载包目录:打开终端输入一下命令
python -m site
#USER_BASE: 这是一个用户本地的基本目录,通常用于安装不需要管理员权限的Python包。
#USER_SITE: 这是用户特定的Python包的安装目录,用于存储用户安装的Python包的模块。
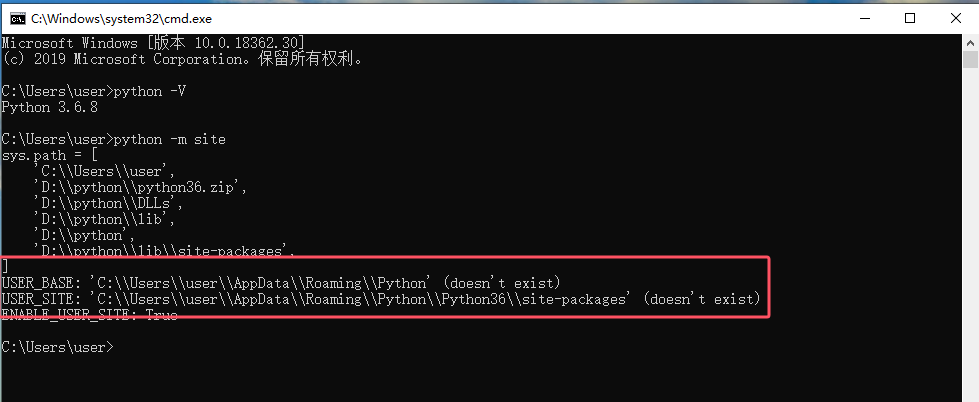
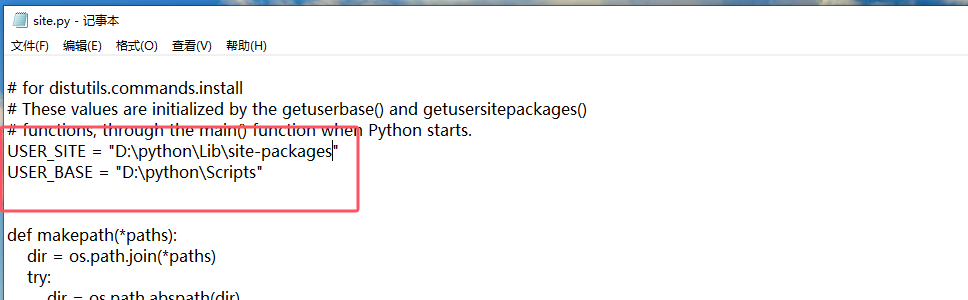
修改site.py存放路径,site.py一般存放在Lib目录
重新打开终端查看
2.Python程序的构成
Python程序----->模块------>语句
1.Python程序是由模块组成,一个源文件就是一个模块,一般后缀为.py。
2.模块由语句组成,运行Python程序时,按照模块中语句的顺序依次运行。
3.语句是Python程序的构造单元,用于创建对象,变量赋值,函数调用,控制语句。
创建一个python程序:创建一个文件夹,在文件夹里面创建一个文本文档
编辑文本文档并保存退出
修改文件名并修改后缀为.py
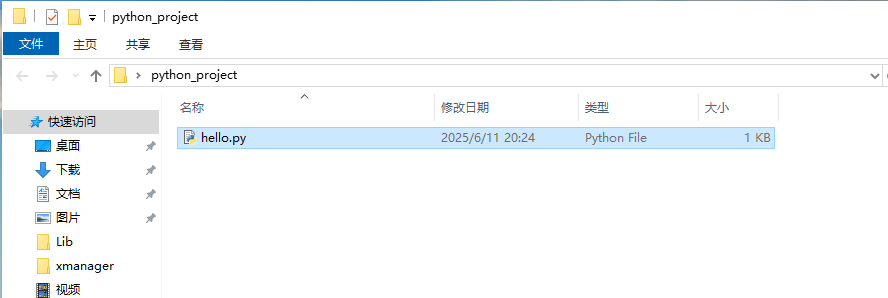
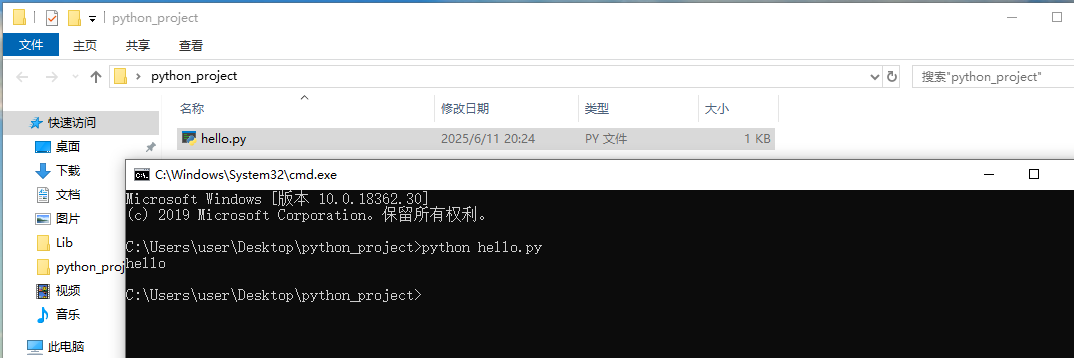
打开终端运行python
3.pycharm安装
PyCharm是一种Python IDE(Integrated Development Environment, 集成开发环境)。它带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自 动完成、单元测试、版本控制。
官网下载地址:https://www.jetbrains.com/pycharm/download/other.html
点击下一步
选择安装路径点击下一步
勾选以下地方
点击完成
双击运行
pycharm基本设置
1.关闭双击shift打开搜索
按ctrl+shift+a ---->搜索registry----> 找到“ide.suppress.double.click.handler”,将后面的复选框勾上
如果以上没有按照下面的方法:
左上角 File -> Settings->Advanced Settings->然后右[输入框输入‘double’ 就可以看到图中最下方的 Shift-Shift 内容。给勾选上即可关闭双击shift弹出搜索框的功能。
2.pycharm配置ctrl+d删除行
左上角 File -> Settings->keymap->在搜索框中输入 Delete Line或者 Remove Line->清除原来的配置->添加自己要的快捷点
3.pycharm配置复制当前行
左上角 File -> Settings->keymap->在搜索框中输入Duplicate Line or Selection->清除原来的配置->添加自己要的快捷点
4.编写一个简单的软件
import turtle
turtle.title("画奥运五环")
turtle.width(10)
turtle.color("black")
turtle.circle(50)
turtle.penup()
turtle.goto(120, 0)
turtle.pendown()
turtle.color("red")
turtle.circle(50)
turtle.penup()
turtle.goto(-120, 0)
turtle.pendown()
turtle.color("blue")
turtle.circle(50)
turtle.penup()
turtle.goto(-60, -60)
turtle.pendown()
turtle.color("yellow")
turtle.circle(50)
turtle.penup()
turtle.goto(60, -60)
turtle.pendown()
turtle.color("green")
turtle.circle(50)
turtle.done()
三、print
1.基本的打印规则
print("hello world")
print("python") # 这是两句分开的打印,会打印两行
print("hello world\npython") # 打印的结果会换行
print('''hello world
python''') # 打印的结果会换行
print("hello world
python") # 错误写法
不换行打印
print('hello world',end=" ") # python3里加上end=" ",可以实现不换行打印.这两句只打印一行
print("python")
print("hello world \
python") # 使用\符号连接行,物理上换了行,逻辑上并没有换行。
print("hello world"
"python") # (),[],{}里的多行内容不用\连接,但需要每行引起来;打印出来的结果不换行
2.有颜色的打印
print("\033[31;1;31mhello world\033[0m")
print("\033[31;1;32mhello world\033[0m")
print("\033[31;1;33mhello world\033[0m")
print("\033[31;1;34mhello world\033[0m")
print("\033[31;1;35mhello world\033[0m")
print("\033[31;1;36mhello world\033[0m")
四、注释
注释的作用:在程序中对某些代码进行标注说明 ,增强程序的可读性。
1.单行注释
在# 后面建议添加一个空格 ,然后在写注释的内容
# 这是单行注释
2.多行注释
三引号(三个双引或三个单引)里包含注释内容
"""多行注释"""
五、变量
变量:在内存中开辟一块空间,存储规定范围内的值,值可以改变。通俗的说变量就是给数据起个名字,通过这个 名字来访问和存储空间中的数据。
1.变量的特点
可以反复存储数据 可以反复取出数据 可以反复更改数据
2.变量的命名规则
变量名只能是字母、数字或下划线的任意组合 变量名的第一个字符不能是数字 变量名要有见名知义的效果, 如UserName,user_name 变量名区分大小写
以下关键字不能声明为变量名(关键字是python内部使用或有特殊含义的字符) ['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
3.变量的创建
在python中,每一个变量在使用前都必须赋值,变量赋值后,变量就创建成功了。 变量名 = 值
num=100 # num第一次出现是表示定义这个变量
num=num-10 # 再次出现,是为此变量赋一个新的值
print(num)
两个变量值的交换
#其它语言中可以借助于第三个变量来交换变量 a 和b 的值
#python中可以直接交换,两个变量的值
a=1
b=2
print(a,b)
a,b=b,a
print(a,b)
六、数据类型
1.数字
int 整型(1, 2, -1, -2) float 浮点型(34.678) bool 布尔型(True/False) complex 复数(4+3J, 不应用于常规编程,这种仅了解一下就好
2.字符串
str 单引号和双引号内表示的内容为字符串 “hello world" "12345"
3.列表
list 使用中括号表示 [1, 2, 3, 4]
4.元组
tuple 使用小括号表示 (1, 2, 3, 4)
5.字典
dict 使用大括号表示,存放key-value键值对 {"a":1, "b":2, "c":3}
6.集合
set 也使用大括号表示,但与字典有所不同 {1, 2, 3, 4}
7.类型的转换
| 转换函数 | 说明 |
|---|---|
| int(xxx) | 将xxx转换为整数 |
| float(xxx) | 将xxx转换为浮点型 |
| str(xxx) | 将xxx转换为字符串 |
| list(xxx) | 将xxx转换为列表 |
| tuple(xxx) | 将xxx转换为元组 |
| dict(xxx) | 将xxx转换为字典 |
| set(xxx) | 将xxx转换为集合 |
| chr(xxx) | 把整数[0-255]转成对应的ASCII码 |
| ord(xxx) | 把ASCII码转成对应的整数[0-255] |
示例
age=25
print(type(age)) # int类型
age=str(25)
print(type(age)) # str类型
七、运算符
1.什么是运算符?
运算符分为:算术运算符,赋值运算符,比较运算符,逻辑运算符等
2.算数运算符
举个简单的例子 1 +2 = 3 。 例子中,1 和 2 被称为操作数,"+" 称为运算符。
| 算术运算符 | 描述 | 实例 |
|---|---|---|
| + | 加法 | 1+2=3 |
| - | 减法 | 5-1=4 |
| * | 乘法 | 3*5=15 |
| / | 除法 | 10/2=5 |
| // | 整除 | 10//3=3 不能整除的只保留整数部分 |
| ** | 求幂 | 2**3=8 |
| % | 取余(取模) | 10%3=1 得到除法的余数 |
3.赋值运算符
| 赋值运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,下面的全部为复合运算符 | c =a + b 将a + b的运算结果赋值给c |
| += | 加法赋值运算符 | a += b 等同于 a = a + b |
| -= | 减法赋值运算符 | a -= b 等同于 a = a - b |
| *= | 乘法赋值运算符 | a *= b 等同于 a = a * b |
| /= | 除法赋值运算符 | a /= b 等同于 a = a / b |
| //= | 整除赋值运算符 | a //= b 等同于 a = a // b |
| **= | 求幂赋值运算符 | a ** = b 等同于 a = a ** b |
| %= | 取余(取模)赋值运算符 | a %= b 等同于 a = a % b |
4.比较运算符
| 比较运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于(注意与=赋值运算符区分开) | print(1==1) 返回True |
| != | 不等于 | print(2!=1) 返回True |
| <> | 不等于(同 != ) | print(2<>1) 返回True |
| > | 大于 | print(2>1) 返回True |
| < | 小于 | print(2<1) 返回False |
| >= | 大于等于 | print(2>=1) 返回True |
| <= | 小于等于 | print(2<=1) 返回False |
5.逻辑运算符
| 逻辑运算符 | 描述 | 实例 |
|---|---|---|
| and | x and y | x与y都为True,则返回True;x与y任一个或两个都为False,则返回False |
| or | x or y | x与y任一个条件为True,则返回True |
| not | not x | x为True,返回False; x为False,返回True |
八、判断语句
通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。
1.python单分支判断语句
if 条件: # 条件结束要加:号(不是;号)
执行动作一 # 这里一定要缩进(tab键或四个空格),否则报错
# 没有fi结束符了,就是看缩进
示例
# 判断条件成立就执行
if 3 < 5:
pirnt('我在里面')
print('我在外面')
2.python双分支判断语句
if 判断条件:
执行语句……
else:
执行语句……
示例
# 判断一个条件:如果条件成立,就执行其包含的条件语句或者代码块。如果条件不成立,就执行另外的其包含语句或某个代码块
if 'boy' == 'gril':
print('男女平等')
else:
print('男女不平等')
3.python多分支判断语句
if 条件一:
执行动作一
elif 条件二: # elif 条件后面都要记得加:
执行动作二
else:
执行动作三
示例
# 判断多个条件
x = 1
if x == 1:
print('love')
elif x == 2:
print('love you')
else:
print('no love')
4.if嵌套
# if嵌套
if 条件判断:
if 条件判断:
执行语句
else:
执行语句
else:
条件语句
示例
name=input("what is your name: ")
age=int(input("how old are you: "))
sex=input("what is your sex: ")
if sex=="male":
if age>=18:
print(name,"sir")
else:
print(name,"boy")
else:
print(name,"girl")
九、循环语句
循环可以让你的程序不断的去做同一件事情
常用循环:
while 循环 在给定的判断条件为 true 时执行循环体,否则退出循环体。
for 循环 重复执行语句
1.while循环
基本语法
#基本语法
while 判断条件(condition):
执行语句(statements)……
示例1
x = 'yes'
while x == 'yes':
y = input('你今天有空吗?')
示例2
i = 1
sum = 0
while i <= 100:
sum += i
i += 1
print(sum)
break语句
# break语句可以让循环退出
while True:
a1 = input('好了吗?')
if a1 == 'yes':
break
continue语句
# continue语句跳出本轮循环,还会回来,如果条件成立,就会进行下一轮循环
i = 0
while i < 10:
i +=1
if i % 2 == 0:
continue
print(i)
嵌套循环打印乘法表
i = 1
while i <= 9:
j = 1
while j <= i:
print(j, '*', i, '=', j * i, end=' ')
j += 1
print()
i += 1
2.for循环
基本语法
for 变量 in 可迭代对象:
重复执行的代码
示例
for he_ber in 'heber':
print(he_ber)
range
# for循环的好兄弟range
range(stop)
# range函数,这里是表示0,1,2,3,4,5(不包括6,默认从0开始)
for i in range(6):
print(i)
range(start,stop)
#从5开始到10结束
for i in range(5,10):
print(i)
range(start,stop,step)
#从5开始到10结束指定跨度为2
for i in range(5,10,2):
print(i)
# for也可以使用break和continue语句
for循环嵌套
sum=0
for i in range(4):
for j in range(4):
print("红球{},绿球{},黄绿{}".format(i,j,6-i-j))
sum+=1
print("一共有{}种排列组合方式".format(sum))
打印九九乘法表
for i in range(1,10):
for j in range(1,i+1):
print("{}*{}={}".format(j,i,i*j),end=" ")
print()
十、列表
列表在其他语言中叫做数组,他可以把其他数据类型存入到里面去
1.列表的创建
赋值创建
x = [1, 2, 3, 'hello', 2.5]
print(x)
不赋值创建
x = []
#给列表赋值
x.append(1)
print(x)
list
x = list("heber")
x = list((1, 2, 3, 4, 5))
2.循环遍历列表
x = [1, 2, 3, 'hello', 2.5]
for i in x:
print(i)
3.列表切片
# 如果需要取出元素中某个范围的值就可以使用切片的方式
x = [1, 2, 3, 'hello', 2.5]
# 取出0到3的值
print(x[0:3])
print(x[:3])
print(x[3:])
# 将列表倒叙输出
print(x[::-1])
4.列表增删改查
# 使用append()在末尾添加元素
heber = ['Yuange', 'mulan']
heber.append('daji')
print(heber)
# 使用extend方法可以添加一个可迭代对象
heber = ['Yuange', 'mulan']
heber.extend(['daji', 'donghuang', 'make'])
print(heber)
# 使用切片的方式添加
heber = ['Yuange', 'mulan']
heber[len(heber):] = ['daji']
print(heber)
# 使用insert添加数据
heber = ['Yuange', 'mulan']
heber.insert(2, 'daji')
print(heber)
# 使用remove方法删除元素--remove只会删除存在的元素,否则就会报错,remove只会删除index最小的元素
heber = ['Yuange', 'mulan']
heber.remove('mulan')
print(heber)
# 使用pop方法删除
heber = ['Yuange', 'mulan']
heber.pop(1)
print(heber)
# 使用clear方法清空
heber = ['Yuange', 'mulan']
heber.clear()
print(heber)
# 修改列表内容,这也可以使用切片方式
heber = ['Yuange', 'mulan']
heber[1] = 'daji'
print(heber)
# 将元素从小到大排序
heber = [1, 3, 2, 7, 9, 8]
heber.sort()
print(heber)
# 元素调转顺序
heber = [1, 3, 2, 7, 9, 8]
heber.reverse()
print(heber)
# 查找里面某个元素有几个
heber = [1, 3, 2, 3, 9, 8]
print(heber.count(3))
# 查看元素索引
heber = [1, 3, 2, 3, 9, 8]
print(heber.index(2))
# 使用索引修改元素
heber = [1, 3, 2, 3, 9, 8]
heber[heber.index(2)] = 5
print(heber)
# 复制列表数据给其他变量
heber = [1, 3, 2, 3, 9, 8]
he_ber = heber.copy()
print(he_ber)
5.嵌套列表
# 定义一个嵌套列表
heber = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 访问嵌套列表
heber = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
for i in heber:
for each in i:
print(each, end=' ')
print( )
# 通过下标访问
heber = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
print(heber[0][2])
6.列表推导式
heber = [1, 2, 3, 4, 5]
heber = [i * 2 for i in heber]
print(heber)
十一、元祖
元组既能像列表那样容纳多种数据类型的对象,也拥有字符串不可变的特性 元组就相当于是只读的列表;因为只读,所以没有append,remove,修改等操作方法 它只有两个操作方法:count,index 元组,字符串,列表都属于序列.所以元组也可以切片
1.创建一个元组
列表使用中括号,元组使用小括号
heber = (1, 2, 3, 4, 5)
print(heber)
#元组也可以使用下标获取元素
print(heber[1])
# 元组也可以使用切片
print(heber[:3])
# 元组取元素值数量和坐标和列表是一样的方法
#元组也支持迭代
2.嵌套元组
#创建一个嵌套元组
heber = ((1, 2, 3), (4, 5, 6))
3.推导式
heber = (1, 2, 3, 4, 5)
heber = [each * 2 for each in heber]
print(heber)
十二、字典
字典:是一种key:value(键值对)类型的数据,它是无序的(没有像列表那样的索引,下标).它是通过key来找value 底层就是hash表,查找速度快;如果key相等,会自动去重(去掉重复值)。字典不能用下标值进行切片操作,字典的键key:字典的值,字典是通过键来实现写入和读取的
1.字典的创建
dict1 = {
'stu01': "zhangsan",
'stu02': "lisi",
'stu03': "wangwu",
'stu04': "maliu",
}
print(type(dict1))
print(len(dict1))
print(dict1)
字典创建摩斯密码
c_table = {".-": "A", "-...": "B", "-.-.": "C", "-..": "D",
".": "E", "..-.": "F", "--.": "G", "....": "H",
"..": "I", ".---": "J", "-.-": "K", ".-..": "L",
"--": "M", "-.": "N", "---": "O", ".--.": "P",
"--.-": "Q", ".-.": "R", "...": "S", "-": "T",
"..-": "U", "...-": "V", ".--": "W", "-..-": "X",
"-.--": "Y", "--..": "Z", ".----": "1", "..---": "2",
"...--": "3", "....-": "4", ".....": "5", "-....": "6",
"--...": "7", "---..": "8", "----.": "9", "-----": "0"}
2.字典的常见操作
# 增
dict1["stu05"]="tianqi" # 类似修改,如果key值不存在,则就增加
print(dict1)
# 改
dict1["stu04"]="马六" # 类似增加,如果key值存在,则就修改
print(dict1)
# 字典的增加与修改的写法是一样的,区别就在于key是否已经存在
# 查
print(dict1["stu01"]) # 如果key值不存在,会返回keyerror错误
print(dict1.get("stu01")) # 这种取值方法如果key值不存在,会返回none,不会返回错误
# 删
dict1.pop("stu05") # 删除这条;也可以del dict1["stu05"]来删除
dict1.popitem() # 删除显示的最后一条
dict1.clear() # 清空字典
print(dict1)
# del dict1 # 删除整个字典
十三、集合
在Python中,集合(set)是一个无序的不重复元素序列。它是可迭代的,没有重复元素(每个元素都是唯一的)
集合和字典一样都是使用大括号。但集合没有value,相当于只有字典的key
1.集合主要特点
- 天生去重(去掉重复值)
- 可以增,删(准确来说,集合可以增加删除元素,但不能修改元素的值)
- 可以方便的求交集,并集,补集
2.创建集合的方法
# 第一种方法
heber = {"set1", "set2"}
# 第二种方法集合推导式
{i for i in "heber"}
十四、文件操作
python文件的操作就三个步骤:
- 先open打开一个要操作的文件
- 操作此文件(读,写,追加等)
- close关闭此文件
1.文件访问模式
简单格式: file_object = open(file_path,mode=" ") r 只读模式,不能写(文件必须存在,不存在会报错) w 只写模式,不能读(文件存在则会被覆盖内容(要千万注意),文件不存在则创建) a 追加模式,不能读 r+ 读写模式 w+ 写读模式 a+ 追加读模式 rb 二进制读模式 wb 二进制写模式 ab 二进制追加模式 rb+ 二进制读写模式 wb+ 二进制写读模式 ab+ 二进制追加读模式
示例:只读模式(r)
# 打开文件
f = open("E:\\pythonproject\\lianxi\\test.txt", mode="r", encoding="utf8")
# 读取文件
data = f.read()
# 打印输出
print(data)
#关闭文件
f.close()
示例:只写模式(w)
f=open("/tmp/1.txt",'w') # 只写模式(不能读),文件不存在则创建新文件,如果文件存在,则会复盖原内容(千W要小心)
data=f.read() # 只写模式,读会报错
f.close()
#正确操作
f=open("/tmp/2.txt",'w') # 文件不存在,会帮你创建(类似shell里的 > 符号)
f.write("hello\n") # 不加\n,默认不换行写
f.write("world\n")
f.truncate() # 截断,括号里没有数字,那么就是不删除
f.truncate(3) # 截断,数字为3,就是保留前3个字节
f.truncate(0) # 截断,数字为0,就是全删除
f.flush() # 相当于把写到内存的内容刷新到磁盘(要等到写的数据到缓冲区一定量时才会自动写,用此命令就可以手动要求他写)
f.close()
示例:文件读的循环方法
f = open("/tmp/2.txt", "r")
# 循环方法一:
for index, line in enumerate(f.readlines()):
print(index, line.strip()) # 需要strip处理,否则会有换行
# 循环方法二:这样效率较高,相当于是一行一行的读,而不是一次性全读(如果文件很大,那么一次性全读会速度很慢)
for index, line in enumerate(f):
print(index, line.strip())
f.close()
2.常用写法
这种写法不用单独关闭文件访问
with open("E:\\pythonproject\\lianxi\\test.txt", mode="r", encoding="utf8") as f:
for index, i in enumerate(f):
if index == 2:
print(i.strip())
break
示例:修改httpd配置文件, 要求把httpd.conf里的第42行的监听端口由80改为8080
方法一
# 修改nginx配置文件中80端口修改成443
file_path = "E:\\pythonproject\\lianxi\\nginx.conf"
f = open(file_path, "r+", encoding="utf8")
for i in range(36):
f.readline()
f.seek(f.tell())
f.write(" listen 443;\n")
f.close()
方法二
# 修改nginx配置文件中80端口修改成443
file_path = "E:\\pythonproject\\lianxi\\nginx.conf"
new_lines = []
with open(file_path, mode="r", encoding="utf8") as f:
lines = f.readlines()
print(type(lines))
for i, line in enumerate(lines):
if i == 36: # 第37行(索引从0开始)
# 精确替换监听端口 - 只替换listen指令中的80
if "listen" in line:
# 替换端口并确保配置格式正确
new_line = line.replace("listen 80", "listen 443")
# 处理带分号的情况
new_line = new_line.replace("listen 80;", "listen 443;")
new_lines.append(new_line)
else:
#其他保留原来样式
new_lines.append(line)
# 写回修改
with open(file_path, mode="r+", encoding="utf-8") as f:
f.writelines(new_lines)
print("Nginx配置已更新:80端口已精确修改为443")
十五、函数
1.什么是函数
函数是可以重复使用的代码块,不仅可以代码复用,更能实现代码一致性。一个程序是由一个个任务组成,一个函数就可以代表一个任务或者一个功能。
函数分类:
- 内置函数:如str(),list()等
- 标准库函数:通过import导入的库
- 第三方函数:就是社区下载的库,一样通过import导入
- 用户自定义函数:根据功能需求,自己定义函数
2.函数的定义
格式
def 函数名 ([参数列表]):
'''文档字符串(对函数的说明)'''
函数体
示例
# 函数定义
def test1():
print("heber")
# 函数调用
test1()
3.形参和实参
定义函数的时候我们可以给函数进行参数传递,可以传递形式参数和实际参数
# 函数定义
def test2(a, b):
if a > b:
print(a, "大")
else:
print(b, "大")
# 函数调用时这里传递的参数称为实参
test2(1, 2)
4.文档字符串
一般建议在定义的函数附上定义说明,这就是文档字符串
定义
# 函数定义
def test2(a, b):
# 使用三引号进行定义
'''这是一个比较大小的函数'''
if a > b:
print(a, "大")
else:
print(b, "大")
# 函数调用
test2(1, 2)
查看文档字符串
# 函数定义
def test2(a, b):
'''这是一个比较大小的函数'''
if a > b:
print(a, "大")
else:
print(b, "大")
# 函数调用
test2(1, 2)
# 查看文档字符串
help(test2.__doc__)
5.函数返回值
如果函数体重包含return语句,则结束函数执行并返回值
如果函数体中不包含return则返回none值
要返回多个返回值,使用列表,元祖,字典,集合将多个值存起来即可
示例
# 返回值的基本使用
def test3(a, b):
print("两个数的和为:{0}".format((a+b)))
print("两个数的和为:", a + b)
return a + b
test3(1, 2)
十六、模块
模块就是一个.py结尾的python代码文件(文件名为hello.py,则模块名为hello), 用于实现一个或多个功能
1.模块分类
模块分为
- 标准库(python自带的模块,可以直接调用)
- 开源模块(第三方模块,需要先pip安装,再调用)
- 自定义模块(自己定义的模块)
模块主要存放在/usr/local/lib/python3.6/目录下,还有其它目录下。使用sys.path查看。
2.模块的导入
# import导入单模块
import hello
# import导入多模块
import module1,module2,module3
# from导入模块里所有的变量,函数,这种导入方式不用再写模块名,直接调用函数即可
from hello import *
# from导入模块文件里的部分函数,这种导入模块中部分函数
from hello import funct1,funct2
# 利用别名来解决模块与本地函数冲突的问题
from hello import funct1 as funct1_hello
3.OS模块
import os
print(os.getcwd()) # 查看当前目录
os.chdir("/tmp") # 改变当前目录
print(os.curdir) # 打印当前目录.
print(os.pardir) # 打印上级目录..
os.chdir(os.pardir) # 切换到上级目录
print(os.listdir("/")) # 列出目录里的文件,结果是相对路径,并且为list类型
print(os.stat("/etc/fstab")) # 得到文件的状态信息,结果为一个tuple类型
print(os.stat("/etc/fstab")[6]) # 得到状态信息(tuple)的第7个元素,也就是得到大小
print(os.stat("/etc/fstab")[-4]) # 得到状态信息(tuple)的倒数第4个元素,也就是得到大小
print(os.stat("/etc/fstab").st_size) # 用这个方法也可以得到文件的大小
print(os.path.getsize(__file__)) # 得到文件的大小,__file__是特殊变量,代表程序文件自己
print(os.path.getsize("/etc/fstab")) # 也可以指定想得到大小的任意文件
print(os.path.abspath(__file__)) # 得到文件的绝对路径
print(os.path.dirname("/etc/fstab")) # 得到文件的绝对路径的目录名,不包括文件
print(os.path.basename("/etc/fstab")) # 得到文件的文件名,不包括目录
print(os.path.split("/etc/fstab")) # 把dirname和basename分开,结果为tuple类型
print(os.path.join("/etc", "fstab")) # 把dirname和basename合并
print(os.path.isfile("/tmp/1.txt")) # 判断是否为文件,结果为bool类型
print(os.path.isabs("1.txt")) # 判断是否为绝对路径,结果为bool类型
print(os.path.exists("/tmp/11.txt")) # 判断是否存在,结果为bool类型
print(os.path.isdir("/tmp/")) # 判断是否为目录,结果为bool类型
print(os.path.islink("/etc/rc.local")) # 判断是否为链接文件,结果为bool类型
os.rename("/tmp/1.txt", "/tmp/11.txt") # 改名
os.remove("/tmp/11.txt") # 删除
os.mkdir("/tmp/aaa") # 创建目录
os.rmdir("/tmp/aaa") # 删除目录
os.makedirs("/tmp/a/b/c/d") # 连续创建多级目录
os.removedirs("/tmp/a/b/c/d") # 从内到外一级一级的删除空目录,目录非空则不删除
os.popen()和os.system()可以直接调用linux里的命令,二者有一点小区别:
# 下面这两句执行操作都可以成功
os.popen("touch /tmp/222")
os.system("touch /tmp/333")
print(os.popen("cat /etc/fstab").read()) # 通过read得到命令的内容,可直接打印出内容,也可以赋值给变量
print(os.system("cat /etc/fstab")) # 除了执行命令外,还会显示返回值(0,非0,类似shell里$?判断用的返回值)
# 所以如果是为了得到命令的结果,并想对结果赋值进行后续操作的话,就使用os.popen(cmd).read()
4.sys模块
print(sys.path) # 模块路径
print(sys.version) # python解释器版本信息
print(sys.platform) # 操作系统平台名称,如linux
sys.argv[n] # sys.argv[0]等同于shell里的$0, sys.argv[1]等同于shell里的$1,以此类推
sys.exit(n) # 退出程序,会引出一个异常
sys.stdout.write('hello world') # 不换行打印
5.random模块
import random
print(random.random()) # 0-1之间的浮点数随机
print(random.uniform(1,3)) # 1-3间的浮点数随机
print(random.randint(1,3)) # 1-3整数随机
print(random.randrange(1,3)) # 1-2整数随机
print(random.randrange(1,9,2)) # 随机1,3,5,7这四个数,后面的2为步长
print(random.choice("hello,world")) # 字符串里随机一位,包含中间的逗号
print(random.sample("hello,world",3)) # 从前面的字符串中随机取3位,并做成列表
list=[1,2,3,4,5]
random.shuffle(list) # 把上面的列表洗牌,重新随机
print(list)
6.psutil模块
import psutil
# cpu
print(psutil.cpu_times()) # 查看cpu状态,类型为tuple
print(psutil.cpu_count()) # 查看cpu核数,类型为int
# memory
print(psutil.virtual_memory()) # 查看内存状态,类型为tuple
print(psutil.swap_memory()) # 查看swap状态,类型为tuple
# partition
print(psutil.disk_partitions()) # 查看所有分区的信息,类型为list,内部为tuple
print(psutil.disk_usage("/")) # 查看/分区的信息,类型为tuple
print(psutil.disk_usage("/boot")) # 查看/boot分区的信息,类型为tuple
# io
print(psutil.disk_io_counters()) # 查看所有的io信息(read,write等),类型为tuple
print(psutil.disk_io_counters(perdisk=True)) # 查看每一个分区的io信息,类型为dict,内部为tuple
# network
print(psutil.net_io_counters()) # 查看所有网卡的总信息(发包,收包等),类型为tuple
print(psutil.net_io_counters(pernic=True)) # 查看每一个网卡的信息,类型为dict,内部为tuple
# process
print(psutil.pids()) # 查看系统上所有进程pid,类型为list
print(psutil.pid_exists(1)) # 判断pid是否存在,类型为bool
print(psutil.Process(1)) # 查看进程的相关信息,类型为tuple
# user
print(psutil.users()) # 查看当前登录用户相关信息,类型为list
7.paramiko模块
paramiko模块支持以加密和认证的方式连接远程服务器。可以实现远程文件的上传,下载或通过ssh远程执行命令
import paramiko
# 创建一个客户端连接实例
ssh = paramiko.SSHClient()
# 加了这一句,如果第一次ssh连接要你输入yes,也不用输入了
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy)
# 指定连接的ip, port, username, password
ip = "192.168.193.131"
port = 22
username = "root"
password = "123456"
ssh.connect(hostname=ip, port=port, username=username, password=password)
# 执行一个命令,有标准输入,输出和错误输出
stdin, stdout, stderr = ssh.exec_command("touch /tmp/123")
# 标准输出赋值
cor_res = stdout.read()
# 错误输出赋值
err_res = stderr.read()
# 没有错误就把正确输出赋值给result,否则就把错误输出赋值给result
if cor_res:
result = cor_res
else:
result = err_res
# 网络传输是二进制需要decode
print(result.decode())
ssh.close()
8.pymysql模块
import pymysql
db=pymysql.connect(host="localhost",user="root",password="",port=3306)
cursor=db.cursor()
cursor.execute("create database aaa;")
cursor.execute("use aaa;")
cursor.execute("create table emp(ename varchar(20),sex char(1),sal int)")
cursor.execute("desc emp")
print(cursor.fetchall())
cursor.close()
db.close()
十七、异常处理
异常处理: Python程序运行语法出错会有异常抛出 不处理异常会导致程序终止
1.异常种类
| 异常种类 | 描述 |
|---|---|
| IndentationError | 缩进对齐代码块出现问题 |
| NameError | 自定义标识符找不到 |
| IndexError | 下标错误 |
| TypeError | 类型错误 |
2.try语句
- 首先,执行try子句(在关键字try和关键字except之间的语句)。
- 如果没有异常发生,忽略except子句,try子句执行后结束。
- 如果在执行try子句的过程中发生了异常,那么try子句余下的部分将被忽略。
- 如果异常的类型和 except 之后的名称相符,那么对应的except子句将被执行。最后执行 try 语句后的代码。
- 如果一个异常没有与任何的except匹配,那么这个异常将会报错并终止程序。
num = input("请输入一个数字:")
try:
num = int(num)
except ValueError:
print("你输的不是数字!")
exit()
print(num)
示例2
list1 = [1, 2, 3]
try:
# 这里两句,从上往下执行,只要发现错误就不继续往下try了,而是直接执行后面的except语句
print(list1[3])
print(list1[0])
except TypeError as err:
print("error1", err)
except IndexError as err:
print("error2:", err)
十八、面向对象
面向对象三大特性:
- 封装2. 继承3. 多态
1.类
python中一切皆对象,类也是一个对象,一类里面包含方法(函数),属性。类和函数就是一种封装。
类的构成 类的名称: 类名 类的属性: 一组参数数据 类的方法: 操作的方式或行为
1.定义一个类
class Student: # 首字母大写
pass
2.给类添加属性
class Student: # 首字母大写
#给类添加属性
def __init__(self, name, score):
self.name = name
self.score = score
s1 = Student("heber", 90)
print(s1.name,s1.score)
3.给类添加方法
class Student: # 首字母大写
def __init__(self, name, score):
self.name = name
self.score = score
def say_score(self):
print("{0}的分数是:{1}".format(self.name, self.score))
s1 = Student("heber", 90)
s1.say_score()
4.私有属性和方法
class Student: # 首字母大写
def __init__(self, name, score):
self.name = name
#在java中私有和公有是private,pubilc。在python中使用__
self.__score = score
def say_score(self):
print("{0}的分数是:{1}".format(self.name, self.__score))
#私有方法
def __say_score1(self):
print("{0}的分数是:{1}".format(self.name, self.__score))
s1 = Student("heber", 90)
s1.say_score()
2.继承
子类可以继承父类的属性方法
继承的作用: 减少代码的冗余**,**便于功能的升级(原有的功能进行完善)与扩展(原没有的功能进行添加)
示例
#父类
class People(object):
def __init__(self,name,age):
self.name = name
self.age = age
def eat(self):
print("{}吃".format(self.name))
def drink(self):
print("{}喝".format(self.name))
#子类
class Man(People):
pass
#子类
class Woman(People):
pass
m1 = Man("xx", 16)
#子类调用父类的方法属性
m1.eat()
w1 = Woman("xxx", 20)
w1.drink()
1.方法重写
class People(object):
def __init__(self,name,age):
self.name = name
self.age = age
def eat(self):
print("{}吃".format(self.name))
def drink(self):
print("{}喝".format(self.name))
class Man(People):
#重写父类的方法
def eat(self):
print("{}拼命吃".format(self.name))
class Woman(People):
pass
m1 = Man("xx", 16)
#调用重写的方法
m1.eat()
2.属性重构
class People(object):
def __init__(self,name,age):
self.name = name
self.age = age
def eat(self):
print("{}吃".format(self.name))
def drink(self):
print("{}喝".format(self.name))
class Man(People):
#重写父类的方法
def eat(self):
print("{}拼命吃".format(self.name))
class Woman(People):
#重构属性
def __init__(self,name,age,love):
self.name = name
self.age = age
self.love = love
def loves(self):
print("{}喜欢{}".format(self.name,self.love))
m1 = Man("xx", 16)
#调用重写的方法
m1.eat()
w1 = Woman("xxx","20","包包")
w1.loves()